A transformation pipeline refers to a structured arrangement that includes a Directed Acyclic Graph (DAG) of transformation functions. Users can interactively select the necessary transformation functions by employing a drag-and-drop interface along with configurable setting blocks. These blocks can be connected to establish the flow of data through the pipeline. This intuitive setup allows users to easily manipulate and visualize the sequence and interaction of data transformations, facilitating a clear and efficient process for data manipulation and analysis.
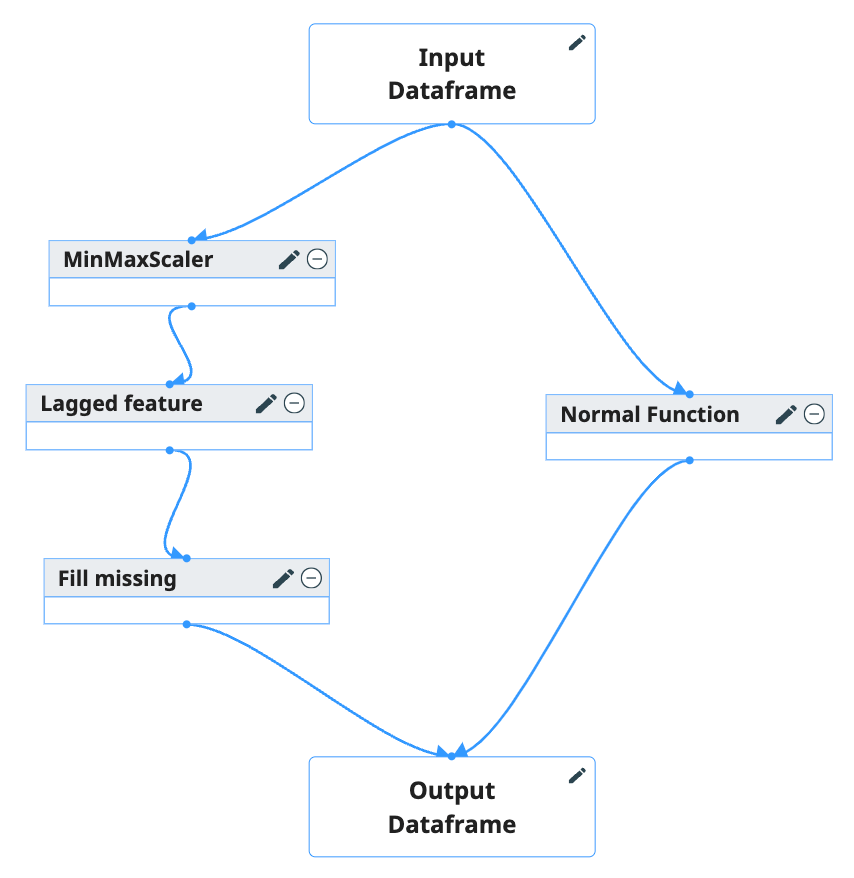

The below table show the configurable items for blocks
| Configurable Items | Description | |
|---|---|---|
| Input Data frame | Get from dataset | Access and generate features from an existing dataset, represented in tabular format |
| Features |
Users can add rows to this table, with each row containing the following elements:
|
|
| Transformation block | Features |
This table also displays the features inputted from connected preceding blocks (referred to as “Father blocks”), indicating the sources of the data. Users have the option to select specific rows for processing by ticking a checkbox at the beginning of each row. For example, in this scenario described, the block receives inputs for features att0, att1, att2, att3. However, the user has configured it to process only att0, att1, and att3. 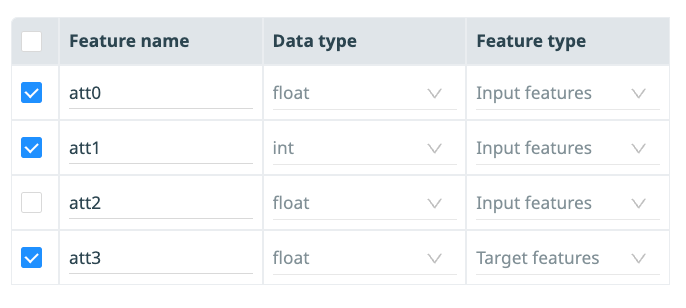
|
| Config | Some transformation functions include configurable variables, defined as environment variable that allow behavior at runtime. User can adjust these configurations to align with the specific logic required by the block function. | |
| Output Data frame | Features | It shows that the expected columns of all pipeline with current configurations. User can imagine that what is the output of pipeline. |
| Config | This is a JSON file contains information about pipeline during runtime, enabling the data pipeline to pass information to the training job through this JSON file. | |